Using Ansible Automation Platform, GitLab CE and webhooks to deploy IIS website
Using Ansible Automation Platform, GitLab CE and webhooks to deploy IIS website
Inside Red Hat Ansible Automation Platform, the Ansible Tower REST API is the key mechanism that helps enable automation to be integrated into processes or tools that exist in an environment. With Ansible Tower 3.6 we have brought direct integration with webhooks from GitHub and GitLab, including the enterprise on-premises versions. This means that changes in source control can trigger automation to apply changes to infrastructure configuration, deploy new services, reconfigure existing applications, and more. In this blog, I'll run through a simple scenario and apply the new integrated webhook feature.
Environment
My environment consists of Ansible Tower (one component of Red Hat Ansible Automation Platform), GitLab CE with a project already created, and a code server running an IDE with the same git repository cloned. A single inventory exists on Ansible Tower with just one host, an instance of Windows 2019 Server running on a certified cloud. For this example, I'm going to deploy IIS on top of this Windows server and make some modifications to the html file that I'd like to serve from this site.
My playbook to deploy IIS is very simple:
--- - name: Configure IIS hosts: windows tasks: - name: Install IIS win_feature: name: Web-Server state: present - name: Start IIS service win_service: name: W3Svc state: started - name: Create website index.html win_copy: src: files/web.html dest: C:\Inetpub\wwwroot\index.html
All that I am doing here is adding the Web-Server feature, starting
IIS and copying my site's html file to the default location for web
content being served by IIS.
My html file is just as basic:
<html> <title></title> <body> </body> </html>
Objective and setup
What I would like to happen is that, for each merge request that makes changes to this one IIS site, the site should be redeployed with this basic html file.

GitLab Access Token
As my webhook is triggered, I would like to update the merge request created in GitLab with the status of my Ansible Tower job.
To accomplish this, I first have to create a personal access token for my GitLab account so that Ansible Tower can access the GitLab API. This is pretty painless. All I have to do is navigate to my user settings and select "Access Tokens" from the left side navigation panel:
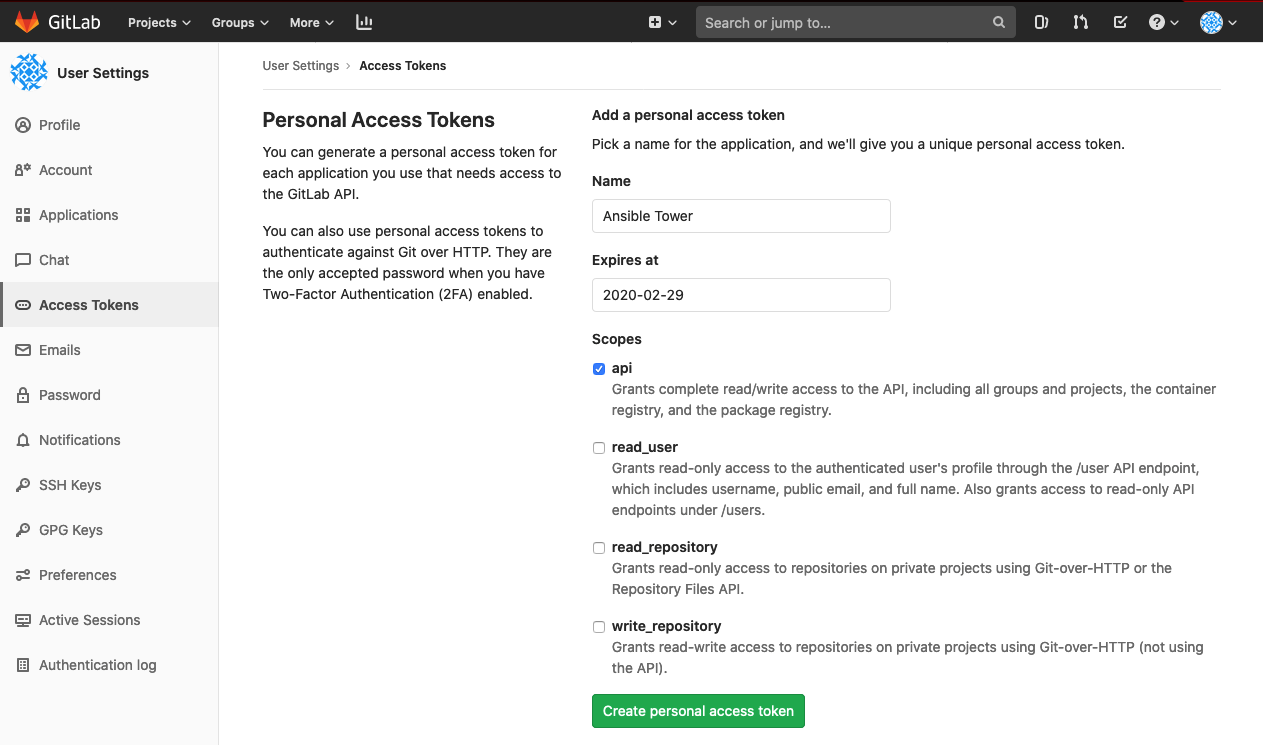
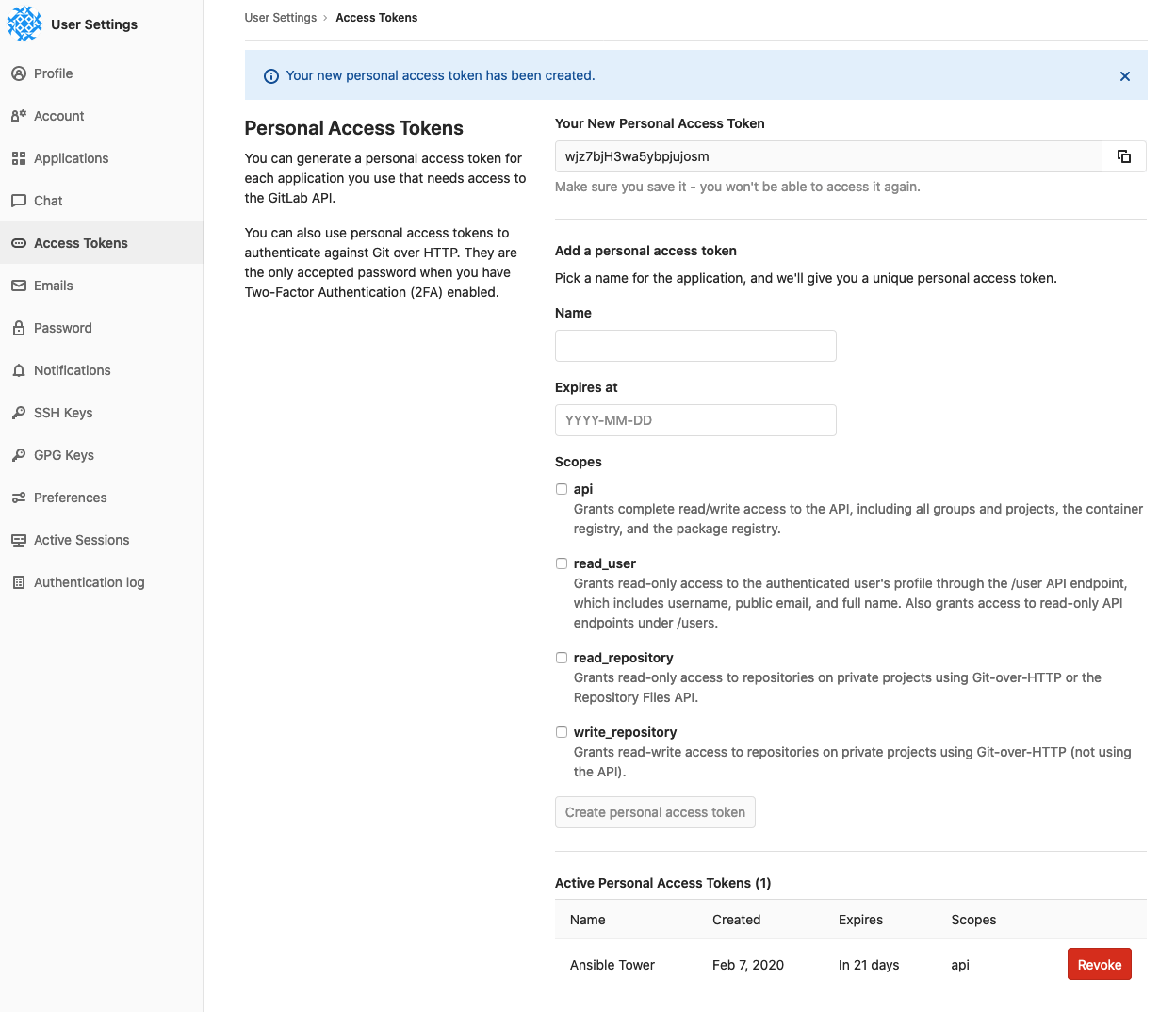
I give my access token an easily recognizable name of "Ansible Tower," set the expiration date to the end of the month, and scope this access token to just the API. Upon clicking "Create personal access token," the token itself becomes visible and a new entry is shown at the bottom of this page:
Next, I will use this token to create a new credential in Ansible Tower of type "GitLab Personal Access Token":
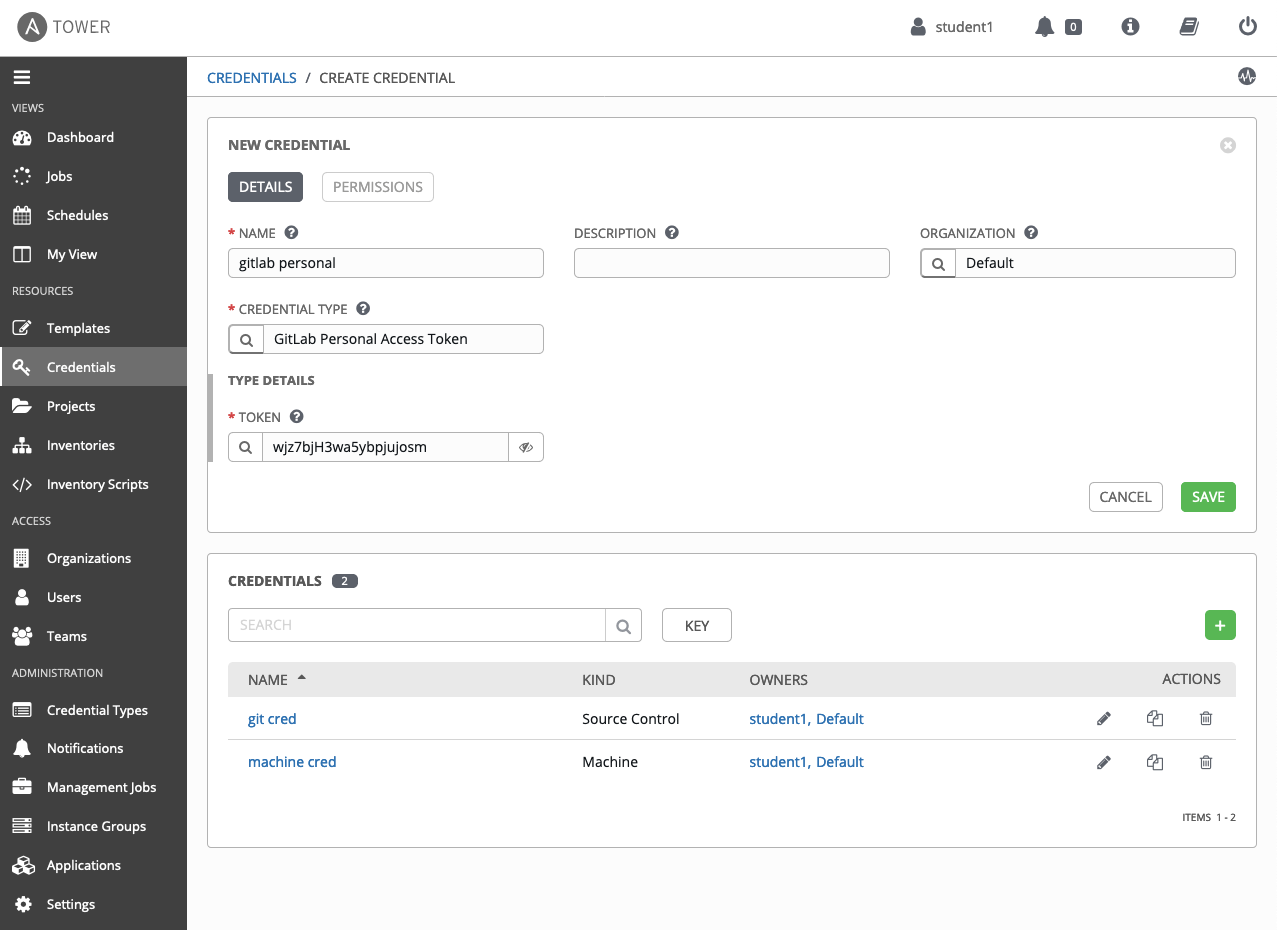
Upon saving, Ansible Tower now has API access to my GitLab account.
Ansible Tower Job Template
Now that Ansible Tower has the ability to update my merge requests, I need to configure webhook access to my job template that is configured to run my simple IIS playbook. Since the Ansible Tower 3.6 release, there is now a checkbox on each job template called ENABLE WEBHOOK.
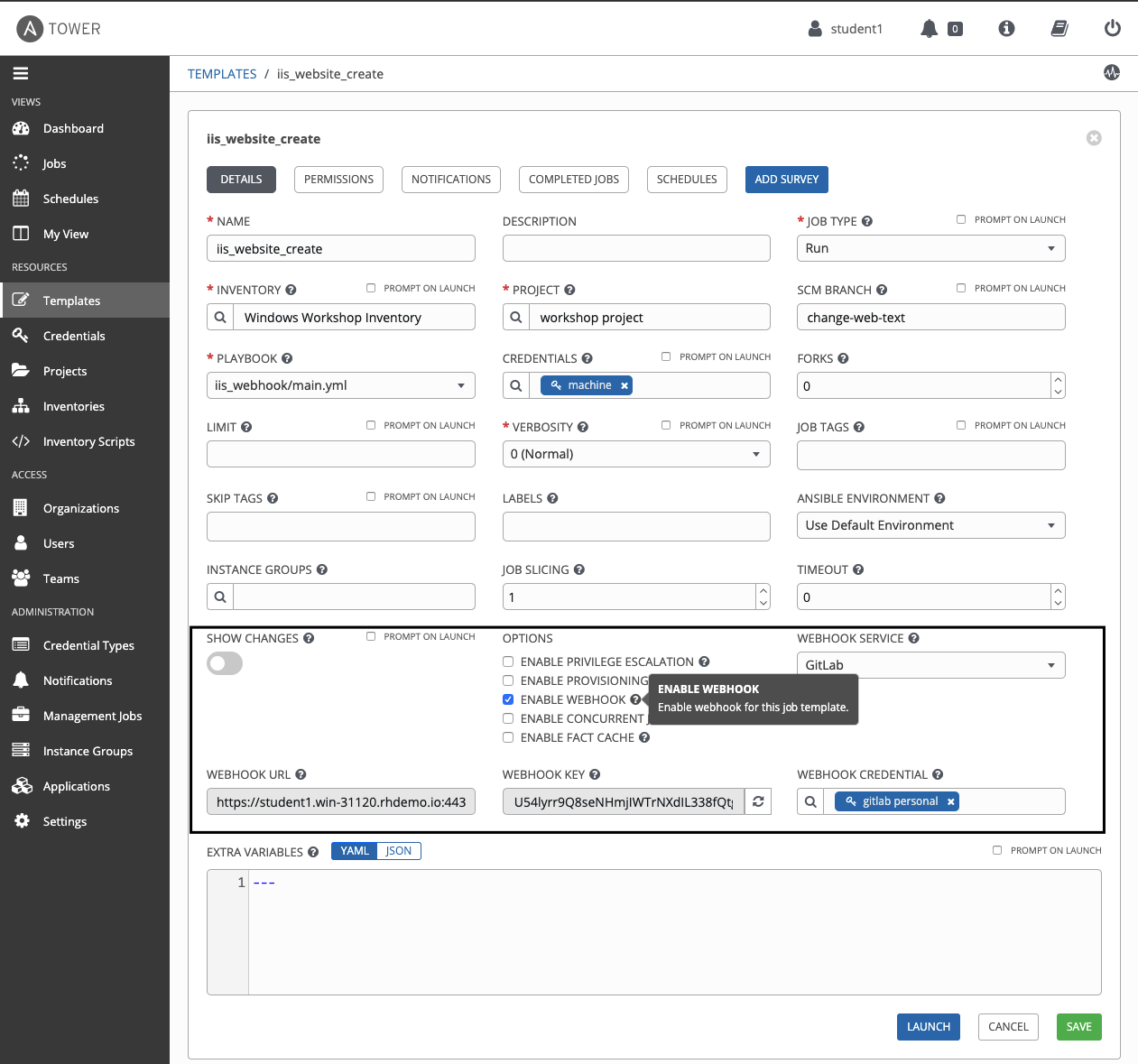
Once I select the option to ENABLE WEBHOOK I am presented with a few new fields. I select GitLab as my WEBHOOK SERVICE, supply the credential I created using my GitLab personal access token, WEBHOOK URL is prepopulated with the path to this job template and, upon saving my modifications, a WEBHOOK KEY is generated which I will use to configure the project hook in GitLab. Also, note that my project allows me to override the SCM branch. This means that the project will pull updates from the "change-web-text" branch instead of Master.
GitLab Project Hook integration
The next step takes me back to GitLab, this time navigating to the integrations page of the project I would like to execute the webhook.
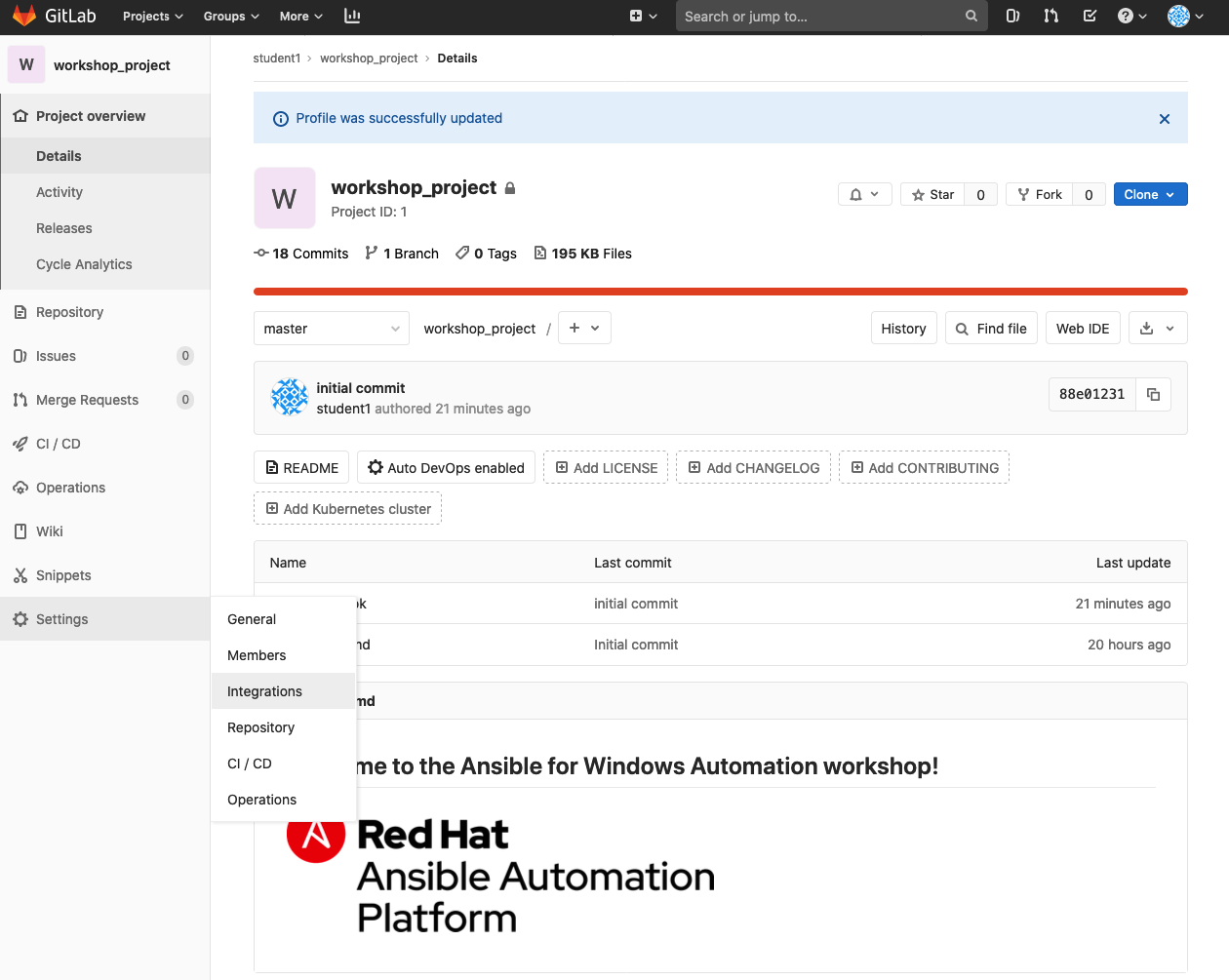
On the integrations page, I supply the URL (WEBHOOK URL from my job template in Ansible Tower) and Secret Token (WEBHOOK KEY from my job template in Ansible Tower). I also specify the Trigger as "Merge request events" which means that the URL I specified will be launched anytime a merge request is opened.
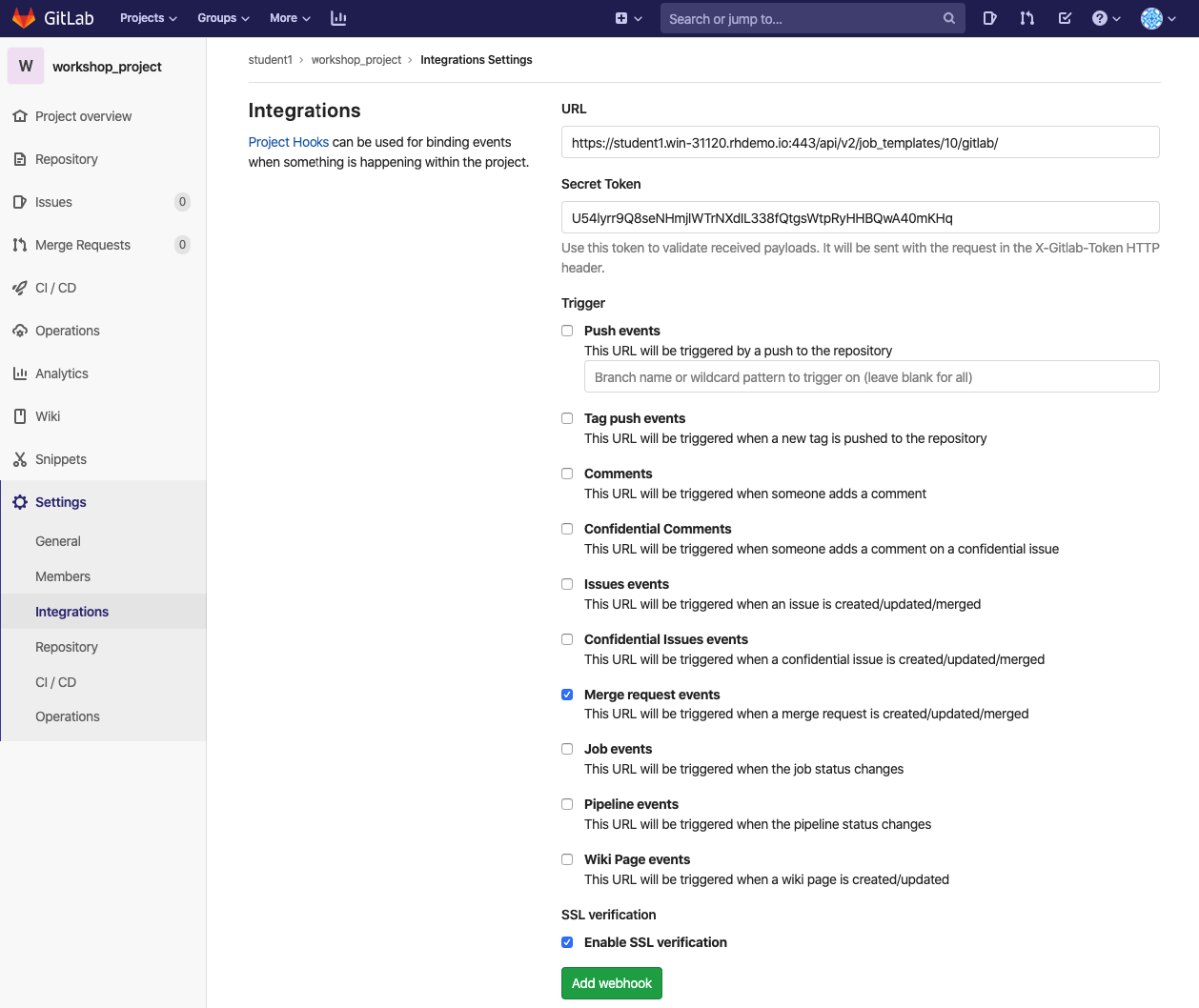
In action: Updating my website text
Now that I've given Ansible Tower access to my projects using a personal access token as a new credential type, configured my job template to enable webhooks, and configured a Project Hook on GitLab to respond to merge request events on my project, I'm ready to make a test commit of my html file.
Here, I add text to the <title> and <body> tags of my html
document and save the file:
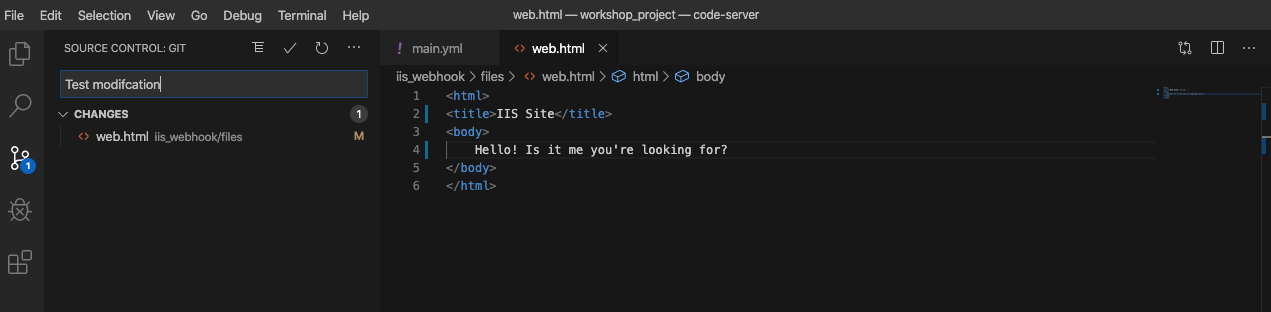
Once I've committed my change on my "change-web-text" branch, I will push my code, go back to GitLab and open a merge request to merge changes back into master.
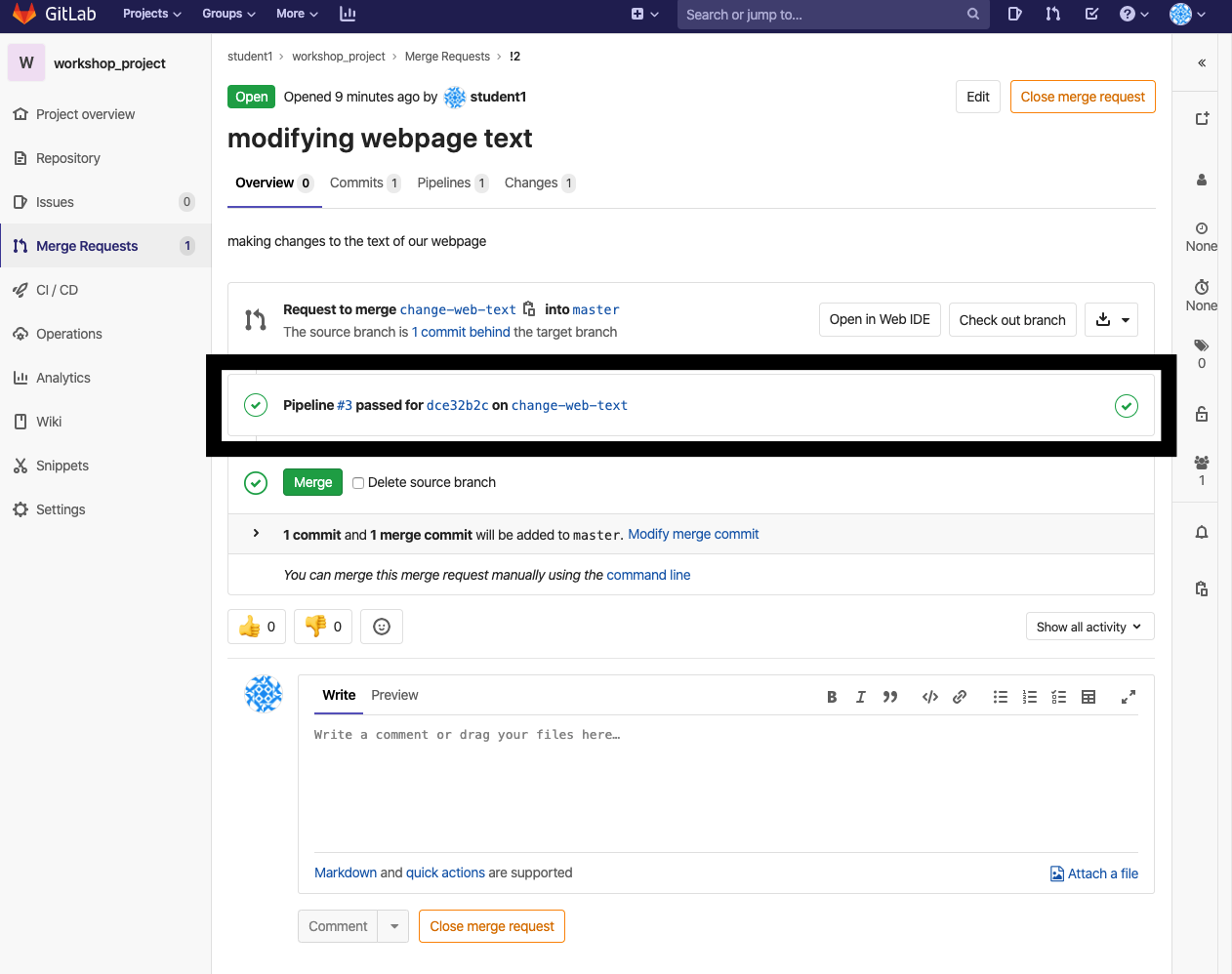
Opening this merge request will now trigger my webhook which will deploy my web page changes to my IIS site. Because I have configured Ansible Tower with my personal access token, Ansible Tower will post a link to the job executed as a result of the webhook trigger on the merge request.
If all has been configured correctly, I should see a new job being executed that corresponds to the job template with the configured webhook. I should also see a job that has been kicked off, updating my project which will pull in the latest changes from my GitLab project.
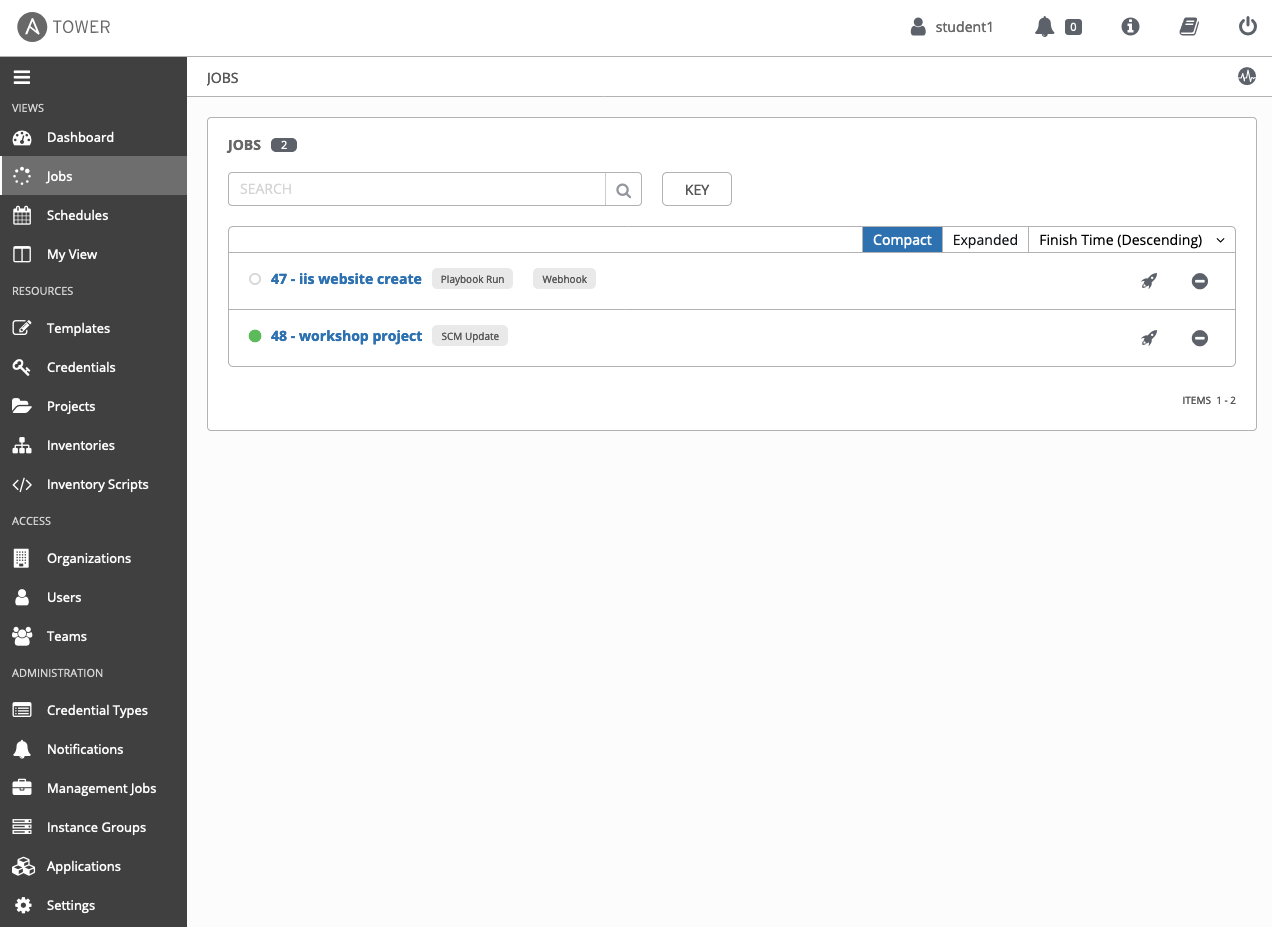
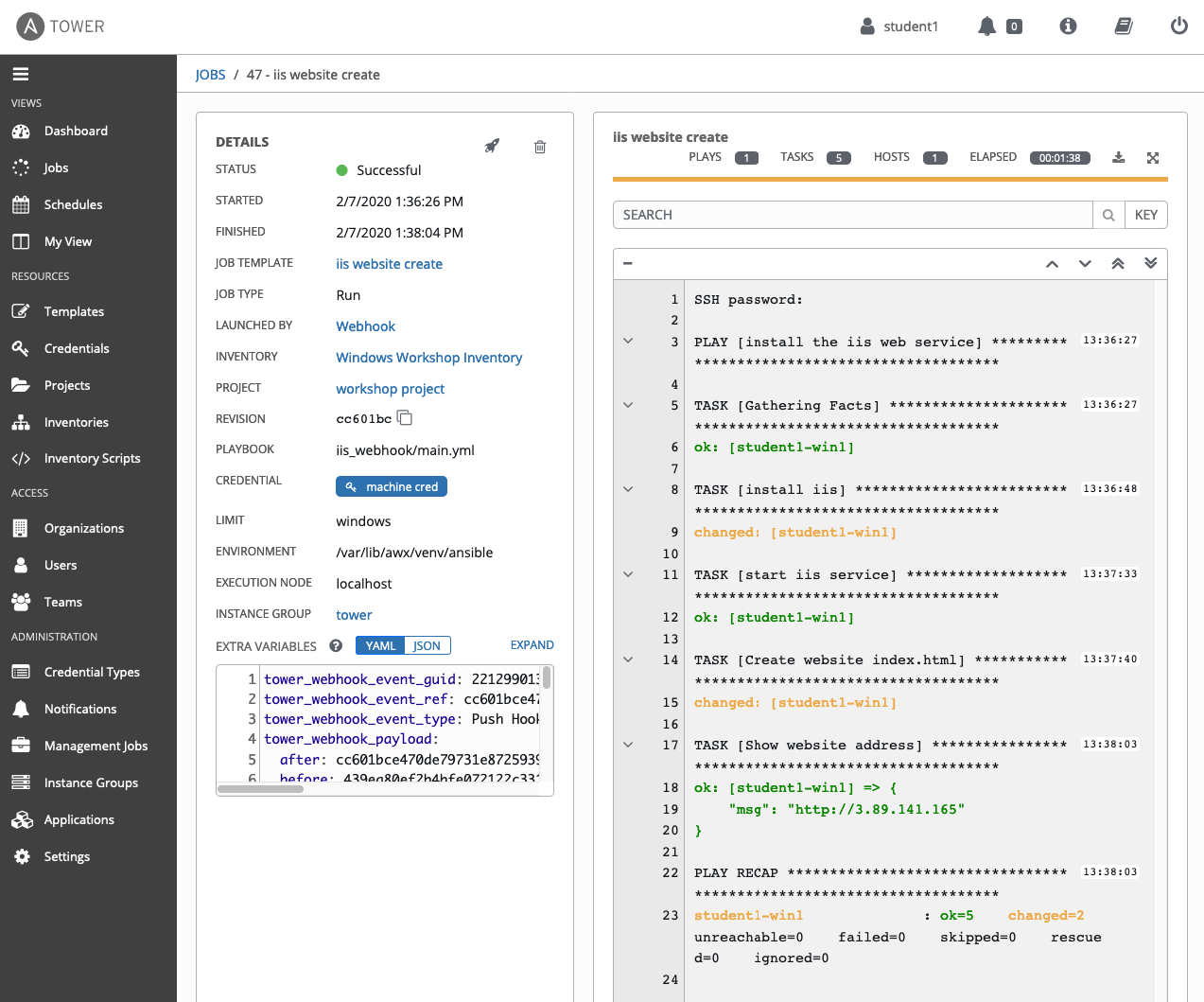
Selecting the job for "iis website create", which is the job template I configured for webhook execution, shows that the job was LAUNCHED BY webhook. EXTRA VARIABLES will show a lot of project specific configuration facts, and more importantly the job output should show that the job is executing what it's supposed to.
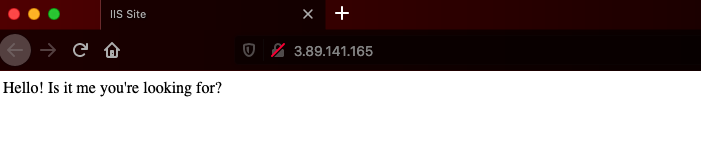
Upon completion, I should be able to pull up the IP of my IIS server and see the changes to my incredible html page:
Takeaways
Webhooks introduced in Ansible Tower 3.6 are an incredibly powerful way to launch automation in response to events in source control. While this basic website is just a very quick and simple example, applying this functionality to infrastructure as code where all service configurations are defined in Ansible Playbooks greatly emphasizes this robust feature.