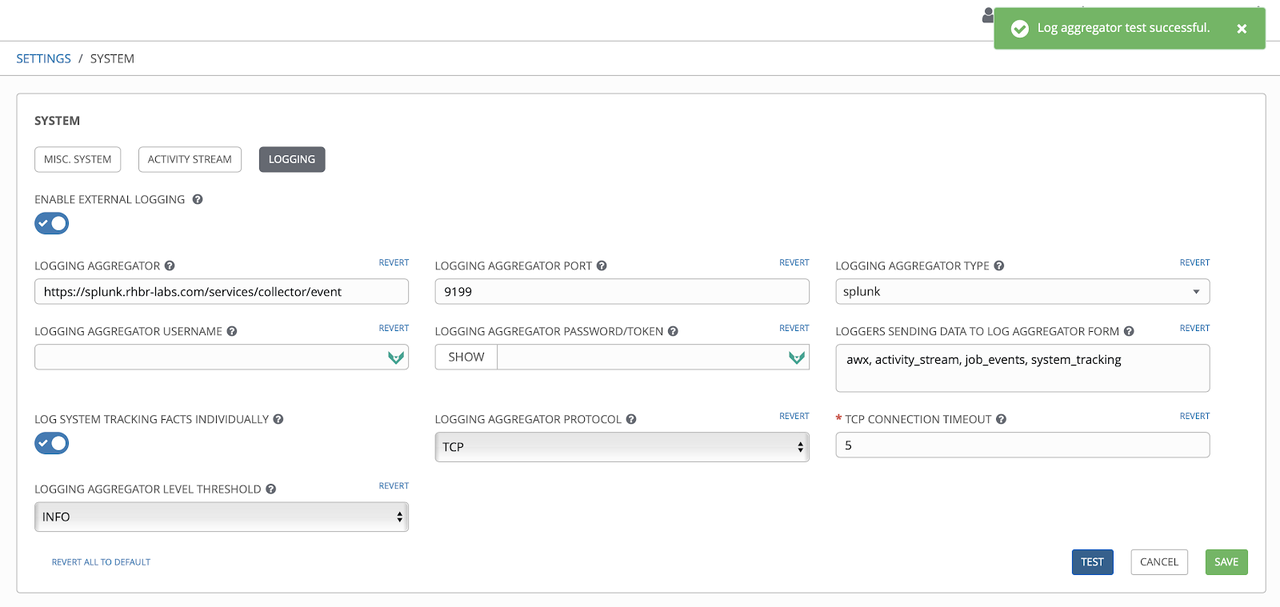
Deep dive on Cisco ASA resource modules
Recently, we published our thoughts on resource modules applied to
the use cases targeted by the Ansible security automation initiative.
The principle is well known from the network automation
space and we follow the established path. While the last blog post
covered a few basic examples, we'd like to show more detailed use cases
and how those can be solved with resource modules.
This blog post goes in depth into the new Cisco ASA Content Collection,
which was already introduced in the previous article. We will walk
through several examples and describe the use cases and how we envision
the Collection being used in real world scenarios.
The Cisco ASA Certified Content Collection: what is it about?
The Cisco ASA Content Collection provides means to automate the
Cisco Adaptive Security Appliance family of security devices -
short Cisco ASA, hence the name. With a focus on firewall and network
security they are well known in the market.
The aim of the Collection is to integrate the Cisco ASA devices into
automated security workflows. For this, the Collection provides modules
to automate generic commands and config interaction with the devices as
well as resource oriented automation of access control lists (ACLs) and
object groups (OGs).
How to install the Cisco ASA Certified Ansible Content Collection
The Cisco ASA Collection is available to Red Hat Ansible Automation
Platform customers at Automation
Hub, our software as a
service offering on cloud.redhat.com and a
place for Red Hat subscribers to quickly find and use content that is
supported by Red Hat and our technology partners.
Once that is done, the Collection is easily installed:
ansible-galaxy collection install cisco.asa
Alternatively you can also find the collection in Ansible
Galaxy, our open source hub for
sharing content in the community.
What's in the Cisco ASA Content Collection?
The focus of the Collection is on the mentioned modules (and the plugins
supporting them): there are three modules for basic interaction,
asa_facts, asa_cli and asa_config. If you are familiar with other
networking and firewall Collections and modules of Ansible you will
recognize this pattern: these three modules provide the most simple way
of interacting with networking and firewall solutions. Using those,
general data can be received, arbitrary commands can be sent and
configuration sections can be managed.
While these modules already provide a great value for environments where
the devices are not automated at all, the focus of this blog article is
on the other modules in the Collection: the resource modules asa_ogs and
asa_acls. Being resource modules they have a limited scope, but enable
users of the Collection to focus on that particular resource without
being disturbed by other content or configuration items. They also
enable a simpler cross-product automation since other Collections follow
the same pattern.
If you take a closer look, you will find two more modules: asa_ogs and
asa_acls. As mentioned in our first blog post about security automation
resource modules, those are deprecated modules, which previously were
used to configure ACLs and OGs. They are superseded by the resource
modules.
Connect to Cisco ASA, the Collection way
The Collection supports network_cli as a connection type. Together with
the network OS cisco.asa.asa, a username and a password, you are good to
go. To get started quickly, you can simply provide these details as part
of the variables in the inventory:
[asa01]
host_asa.example.com
[asa01:vars]
ansible_user=admin
ansible_ssh_pass=password
ansible_become=true
ansible_become_method=ansible.netcommon.enable
ansible_become_pass=become_password
ansible_connection=ansible.netcommon.network_cli
ansible_network_os=cisco.asa.asa
ansible_python_interpreter=python
Note that in a productive environment those variables should be
supported in a secure way, for example, with the help of Ansible Tower
credentials.
Use Case: ACLs
After all this is setup, we are now ready to dive into the actual
Collections and how they can be used. For the first use case, we want to
look at managing ACLs within ASA. Before we dive into Ansible Playbook
examples, let's quickly discuss what ASA ACLs are and what an automation
practitioner should be aware of.
ASA Access-lists are created globally and are then applied with the
access-group "command". They can either be applied inbound or outbound.
There are few things users should be aware with respect to access-lists
on the Cisco ASA firewall:
-
When a user creates an ACL for higher to lower security level i.e.
outbound traffic then the source IP address is the address of the
host or the network (not the NAT translated one).
-
When a user creates an ACL for lower to higher security level i.e.
inbound traffic then the destination IP address has to be either of
the below two:
-
- The translated address for any ASA version before 8.3.
- The address for ASA 8.3 and newer.
-
The access-list is always checked before NAT translation.
Additionally, changing ACLs can become very complex quickly. It is not
only about the configuration itself, but also the intent of the
automation practitioner: should a new ACL just be added to the existing
configuration? Or should it replace it? And what about merging them?
The answer to these questions usually depends on the environment and
situation the change is deployed in. The different ways of changing ACLs
are noted here and in the Cisco ASA Content Collection as "states":
different ways to deploy changes to ACLs.
The ACLs module knows the following states:
- Gathered
- Merged
- Overridden
- Replaced
- Deleted
- Rendered
- Parsed
In this use case discussion, we will have a look at all of them, though
not always in full detail. However, we will provide links to full code
listings for the interested readers.
Please note that while we usually use network addresses for the source
and destination examples, other values like network object-groups are
also possible.
State Gathered: Populating an inventory with configuration data
Given that resource modules allow to read-in existing network
configuration and convert that into structured data models, the state
"gathered" is the equivalent for gathering Ansible Facts for this
specific resource. That is helpful if specific configuration pieces
should be reused as variables later on. Another use case is to read-in
the existing network configuration and store it as a flat-file. This
flat file can be committed to a git repository on a scheduled base,
effectively tracking the current configuration and changes of your
security tooling.
To showcase how to store existing configuration as a flat file, let's
take the following device configuration:
ciscoasa# sh access-list
access-list cached ACL log flows: total 0, denied 0 (deny-flow-max 4096)
alert-interval 300
access-list test_access; 2 elements; name hash: 0x96b5d78b
access-list test_access line 1 extended deny tcp 192.0.2.0 255.255.255.0 192.0.3.0 255.255.255.0 eq www log default (hitcnt=0) 0xdc46eb6e
access-list test_access line 2 extended deny icmp 198.51.100.0 255.255.255.0 198.51.110.0 255.255.255.0 alternate-address log errors interval 300 (hitcnt=0) 0x68f0b1cd
access-list test_R1_traffic; 1 elements; name hash: 0x2c20a0c
access-list test_R1_traffic line 1 extended deny tcp 2001:db8:0:3::/64 eq www 2001:fc8:0:4::/64 eq telnet (hitcnt=0) 0x11821a52
To gather and store the content as mentioned above, we need to first
gather the data from each device, then create a directory structure
mapping our devices and then store the configuration there, in our case
as YAML files. The following playbook does exactly that. Note the
parameter state: gathered in the first task.
---
- name: convert interface to structured data
hosts: asa
gather_facts: false
tasks:
- name: Gather facts
cisco.asa.asa_acls:
state: gathered
register: gather
- name: Create inventory directory
become: true
delegate_to: localhost
file:
path: "{{ inventory_dir }}/host_vars/{{ inventory_hostname }}"
state: directory
- name: Write each resource to a file
become: true
delegate_to: localhost
copy:
content: "{{ gather[‘gathered’][0] | to_nice_yaml }}"
dest: "{{ inventory_dir }}/host_vars/{{ inventory_hostname }}/acls.yaml"
The state "gathered" only collects existing data. In contrast to most
other states, it does not change any configuration. The resulting data
structure from reading in a brownfield configuration can be seen below:
$ cat lab_inventory/host_vars/ciscoasa/acls.yaml
- acls:
- aces:
- destination:
address: 192.0.3.0
netmask: 255.255.255.0
port_protocol:
eq: www
grant: deny
line: 1
log: default
protocol: tcp
protocol_options:
tcp: true
source:
address: 192.0.2.0
netmask: 255.255.255.0
...
You can the full detailed listing of all the commands and outputs of the
example in the state: gathered reference
gist.
State Merged: Add/Update configuration
After the first, non-changing state we now have a look at a state which
changes the target configuration: "merged". This state is also the
default state for any of the available resource modules - because it
just adds or updates the configuration provided by the user. Plain and
simple.
For example, let's take the following existing device configuration:
ciscoasa# sh access-list
access-list cached ACL log flows: total 0, denied 0 (deny-flow-max 4096)
alert-interval 300
access-list test_access; 1 elements; name hash: 0x96b5d78b
access-list test_access line 1 extended deny tcp 192.0.2.0 255.255.255.0 192.0.3.0 255.255.255.0 eq www log debugging interval 300 (hitcnt=0) 0xdc46eb6e
Let us assume we want to deploy the configuration which we stored as a
flat-file in the gathered example. Note that the content of the flat
file is basically one variable called "acls". Given this flat file and
the variable name, we can use the following playbook to deploy the
configuration on a device:
---
- name: Merged state play
hosts: cisco
gather_facts: false
collections:
- cisco.asa
tasks:
- name: Merge ACLs config with device existing ACLs config
asa_acls:
state: merged
config: "{{ acls }}"
Once we run this merge play all of the provided parameters will be
pushed and configured on the Cisco ASA appliance.
Afterwards, the network device configuration is changed:
ciscoasa# sh access-list
access-list cached ACL log flows: total 0, denied 0 (deny-flow-max 4096)
alert-interval 300
ccess-list test_access; 2 elements; name hash: 0x96b5d78b
access-list test_access line 1 extended deny tcp 192.0.2.0 255.255.255.0 192.0.3.0 255.255.255.0 eq www log default (hitcnt=0) 0xdc46eb6e
access-list test_access line 2 extended deny icmp 198.51.100.0 255.255.255.0 198.51.110.0 255.255.255.0 alternate-address log errors interval 300 (hitcnt=0) 0x68f0b1cd
access-list test_R1_traffic; 1 elements; name hash: 0x2c20a0c
access-list test_R1_traffic line 1 extended deny tcp 2001:db8:0:3::/64 eq www 2001:fc8:0:4::/64 eq telnet (hitcnt=0) 0x11821a52
All the changes we described in the playbook with the resource modules
are now in place in the device configuration.
If we dig slightly into the device output there are following
observations:
-
The merge play configured 2 ACLs:
-
- test_access, configured with 2 Access Control Entries (ACEs)
- test_R1_traffic with only 1 ACEs
-
test_access is an IPV4 ACL where for the first ACE we have specified
the line number as 1 while for the second ACE we only specified the
name which is the only required parameter. All the other parameters
are optional and can be chosen depending on the particular ACE
policies . Note however that it is considered best practice to
configure the line number if we want to avoid an ACE to be
configured as the last in an ACL.
-
test_R1_traffic is an IPV6 ACL
-
As there weren't any pre-existing ACLs on this device, all the play
configurations have been added. If we had any pre-existing ACLs and
the play also had the same ACL with either different ACEs or same
ACEs with different configurations, the merge operation would have
updated the existing ACL configuration with the new provided ACL
configuration.
Another benefit of automation shows when we run the respective merge
play a second time: Ansible's charm of idempotency comes into the
picture! The play run results in "changed=False" which confirms to the
user that all of the provided configurations in the play are already
configured on the Cisco ASA device.
You can the full detailed listing of all the commands and outputs of the
example in the state: merged reference gist.
State Replaced: Old out, new in
Another typical situation is when a device is already configured with an
ACL with existing ACEs, and the automation practitioner wants to update
the ACL with a new set of ACEs while entirely discarding all the already
configured ones.
In this scenario the state "replaced" is an ideal choice: as the name
suggests, the replaced state will replace ACL existing ACEs with a new
set of ACEs given as input by the user. If a user tries to configure any
new ACLs that are not already pre-configured on the device it'll act as
a merge state and the asa_acls module will try to configure the ACL ACEs
given as input by the user inside the replace play.
Let's take the following brown field configuration:
ciscoasa# sh access-list
access-list cached ACL log flows: total 0, denied 0 (deny-flow-max 4096)
alert-interval 300
access-list test_access; 2 elements; name hash: 0x96b5d78b
access-list test_access line 1 extended deny tcp 192.0.2.0 255.255.255.0 192.0.3.0 255.255.255.0 eq www log default (hitcnt=0) 0xdc46eb6e
access-list test_access line 2 extended deny icmp 198.51.100.0 255.255.255.0 198.51.110.0 255.255.255.0 alternate-address log errors interval 300 (hitcnt=0) 0x68f0b1cd
access-list test_R1_traffic; 1 elements; name hash: 0x2c20a0c
access-list test_R1_traffic line 1 extended deny tcp 2001:db8:0:3::/64 eq www 2001:fc8:0:4::/64 eq telnet (hitcnt=0) 0x11821a52
Now we assume we want to configure a new ACL named "test_global_access",
and we want to replace the already existing "test_access" ACL
configuration with a new source and destination IP. The corresponding
ACL configuration for our new desired state is:
- acls:
- name: test_access
acl_type: extended
aces:
- grant: deny
line: 1
protocol: tcp
protocol_options:
tcp: true
source:
address: 192.0.3.0
netmask: 255.255.255.0
destination:
address: 192.0.4.0
netmask: 255.255.255.0
port_protocol:
eq: www
log: default
- name: test_global_access
acl_type: extended
aces:
- grant: deny
line: 1
protocol_options:
tcp: true
source:
address: 192.0.4.0
netmask: 255.255.255.0
port_protocol:
eq: telnet
destination:
address: 192.0.5.0
netmask: 255.255.255.0
port_protocol:
eq: www
Note that the definition is again effectively contained in the variable
"acls" - which we can reference as a value for the "config" parameter of
the asa_acls module just as we did in the last example. Only the value
for the state parameter is different this time:
---
- name: Replaced state play
hosts: cisco
gather_facts: false
collections:
- cisco.asa
tasks:
- name: Replace ACLs config with device existing ACLs config
asa_acls:
state: replaced
config: "{{ acls }}"
After running the playbook, the network device configuration has changed
as intended: the old configuration was replaced with the new one. In
cases where there was no corresponding configuration in place to be
replaced, the new one was added:
ciscoasa# sh access-list
access-list cached ACL log flows: total 0, denied 0 (deny-flow-max 4096)
alert-interval 300
access-list test_access; 1 elements; name hash: 0x96b5d78b
access-list test_access line 1 extended deny tcp 192.0.3.0 255.255.255.0 192.0.4.0 255.255.255.0 eq www log default (hitcnt=0) 0x7ab83be2
access-list test_R1_traffic; 1 elements; name hash: 0x2c20a0c
access-list test_R1_traffic line 1 extended deny tcp 2001:db8:0:3::/64 eq www 2001:fc8:0:4::/64 eq telnet (hitcnt=0) 0x11821a52
access-list test_global_access; 1 elements; name hash: 0xaa83124c
access-list test_global_access line 1 extended deny tcp 192.0.4.0 255.255.255.0 eq telnet 192.0.5.0 255.255.255.0 eq www (hitcnt=0) 0x243cead5
Note that the ACL test_R1_traffic was not modified or removed in this example!
You can the full detailed listing of all the commands and outputs of the
example in the state: replaced reference gist.
State Overridden: Drop what is not needed
As noted in the last example, ACLs which are not explicitly mentioned in
the definition remain untouched. But what if there is the need to
reconfigure all existing and pre-configured ACLs with the input ACL ACEs
configuration - and also affect those that are not mentioned? This is
where the state "overridden" comes into play.
If you take the same brown field environment from the last example and
deploy the same ACL definition against it, but this time switch the
state to "overridden", the resulting configuration of the device looks
quite different:
Brownfield device configuration before deploying the ACLs:
ciscoasa# sh access-list
access-list cached ACL log flows: total 0, denied 0 (deny-flow-max 4096)
alert-interval 300
access-list test_access; 2 elements; name hash: 0x96b5d78b
access-list test_access line 1 extended deny tcp 192.0.2.0 255.255.255.0 192.0.3.0 255.255.255.0 eq www log default (hitcnt=0) 0xdc46eb6e
access-list test_access line 2 extended deny icmp 198.51.100.0 255.255.255.0 198.51.110.0 255.255.255.0 alternate-address log errors interval 300 (hitcnt=0) 0x68f0b1cd
access-list test_R1_traffic; 1 elements; name hash: 0x2c20a0c
access-list test_R1_traffic line 1 extended deny tcp 2001:db8:0:3::/64 eq www 2001:fc8:0:4::/64 eq telnet (hitcnt=0) 0x11821a52
Device configuration after deploying the ACLs via the resource module
just list last time, but this time with state "overridden":
ciscoasa# sh access-list
access-list cached ACL log flows: total 0, denied 0 (deny-flow-max 4096)
alert-interval 300
access-list test_access; 1 elements; name hash: 0x96b5d78b
access-list test_access line 1 extended deny tcp 192.0.3.0 255.255.255.0 192.0.4.0 255.255.255.0 eq www log default (hitcnt=0) 0x7ab83be2
access-list test_global_access; 1 elements; name hash: 0xaa83124c
access-list test_global_access line 1 extended deny tcp 192.0.4.0 255.255.255.0 eq telnet 192.0.5.0 255.255.255.0 eq www (hitcnt=0) 0x243cead5
Note that this time the listing is considerably shorter - the ACL
test_R1_traffic was dropped since it was not explicitly mentioned in the
ACL definition which was deployed. This showcases the difference between
"replaced" and "overridden" state.
You can the full detailed listing of all the commands and outputs of the
example in the state: overridden reference gist.
State Deleted: Remove what is not wanted
Another more obvious use case is the deletion of existing ACLs on the
device, which is implemented in the "deleted" state. In that case the
input is the ACL name to be deleted and the corresponding delete
operation will delete the entry of the particular ACL by deleting all of
the ACEs configured under the respective ACL.
As an example, let's take our brown field configuration already used in
the other examples. To delete the ACL test_access we name it in the
input variable:
- acls:
- name: test_access
The playbook looks just like the one in the other examples, just with
the parameter and value state: deleted. After executing it, the
configuration of the device is:
ciscoasa# sh access-list
access-list cached ACL log flows: total 0, denied 0 (deny-flow-max 4096)
alert-interval 300
access-list test_R1_traffic; 1 elements; name hash: 0x2c20a0c
access-list test_R1_traffic line 1 extended deny tcp 2001:db8:0:3::/64 eq www 2001:fc8:0:4::/64 eq telnet (hitcnt=0) 0x11821a52
The output is clearly shorter than the previous configuration since an
entire ACL is missing.
You can the full detailed listing of all the commands and outputs of the
example in the state: deleted reference gist.
State Rendered and State Parsed: For development and offline work
There are two more states currently available : "rendered" and "parsed".
Both are special in that they are not meant to be used in production
environments, but during development of your playbooks and device
configuration. They do not change the device configuration - instead
they output what would be changed in different formats.
The state "rendered" returns a listing of the commands that would be
executed to apply the provided configuration. The content of the
returned values given the above used configuration against our brown
field device configuration:
"rendered": [
"access-list test_access line 1 extended deny tcp 192.0.2.0 255.255.255.0 192.0.3.0 255.255.255.0 eq www log default",
"access-list test_access line 2 extended deny icmp 198.51.100.0 255.255.255.0 198.51.110.0 255.255.255.0 alternate-address log errors",
"access-list test_R1_traffic line 1 extended deny tcp 2001:db8:0:3::/64 eq www 2001:fc8:0:4::/64 eq telnet"
]
You can the full detailed listing of all the commands and outputs of the
example in the state: rendered reference
gist.
State "parsed" acts similar, but instead of returning the commands that
would be executed, it returns the configuration as a JSON structure,
which can be reused in subsequent automation tasks or by other programs.
See our full detailed listing of all the commands and outputs of the
parsed example in the state: parsed reference
gist.
Use Case: OGs
As mentioned before, the Ansible Content Collection does support a
second resource: object groups. Think of networks, users, security
groups, protocols, services and the like. The resource module can be
used to define them or alter their definition. Much like the ACLs
resource module, the basic workflow defines them via a variable
structure and then deploys them in a way identified by a state
parameter. The states are basically the same as the ACLs resource module
understands.
Due to this similarity, we will not go into further details here but
instead refer to the different state examples mentioned above.
From a security perspective however, the object group resource module is
crucial: in a modern IT environment, communication relations are not
only defined by IP addresses, but can also be defined by the types of
objects that are in focus: it is crucial for security practitioners to
be able to abstract those types in object groups and address their
communication relations in ACLs later on.
This also explains why we picked these two resource modules to start
with: they work closely hand in hand and together pave the way for an
automated security approach using the family of Cisco ASA devices.